
r语言 系统聚类,R语言系统聚类方法应用概述
时间:2024-12-26 来源:网络 人气:
你有没有想过,数据就像是一群神秘的小精灵,它们在电脑的硬盘里跳来跳去,等待着被你唤醒,揭示它们隐藏的秘密?而我今天要和你分享的,就是如何用R语言这个神奇的魔法棒,把这群小精灵聚集成一个个有趣的群体——系统聚类!
系统聚类:数据的魔法聚会
想象你站在一个巨大的聚会现场,每个人都是来自不同背景的数据点。他们有的高,有的矮,有的胖,有的瘦,有的活泼,有的沉默。你想要把他们分成几个小组,让相似的人在一起玩耍。这时候,系统聚类就派上用场了!
系统聚类,顾名思义,就是按照一定的规则,把相似的数据点聚在一起,形成一个个小组。这个过程就像是在举办一场魔法聚会,把相似的人邀请到同一个房间,让他们成为好朋友。
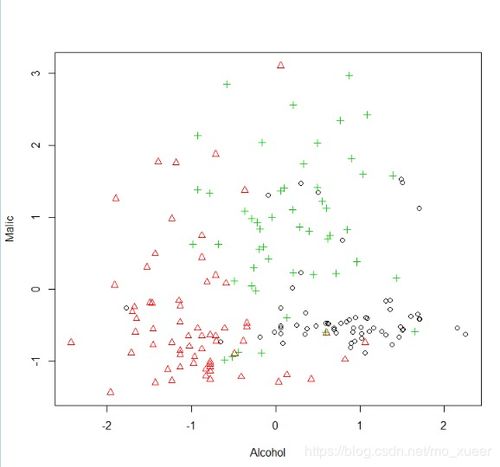
聚类的魔法:距离的奥秘
在系统聚类中,距离是衡量数据点相似程度的关键。你可以把距离想象成两个人之间的距离,距离越近,关系越亲密。在R语言中,我们可以使用`dist`函数来计算数据点之间的距离。

距离的彩虹:欧氏距离、曼哈顿距离、马氏距离……
R语言提供了多种距离计算方法,比如欧氏距离、曼哈顿距离、马氏距离等等。这些方法就像彩虹一样,各有各的特色。
- 欧氏距离:想象你在二维空间中,两点之间的直线距离。
- 曼哈顿距离:想象你在曼哈顿街头,两点之间的直线距离,但只能沿着街道走。
- 马氏距离:考虑了数据点的协方差矩阵,更适用于多维数据。
选择哪种距离方法,取决于你的数据和需求。
聚类的色彩:层次聚类树
当计算完数据点之间的距离后,我们就可以开始聚类了。R语言中的`hclust`函数可以帮助我们绘制层次聚类树,它就像是一幅色彩斑斓的画卷,展示了数据点之间的亲疏关系。
树的奥秘:凝聚层次聚类
层次聚类是一种自底向上的聚类方法,它从每个数据点开始,逐渐合并相似的数据点,直到形成一个大的聚类。这个过程就像是一棵树的生长,从树根到树梢,逐渐形成完整的树冠。
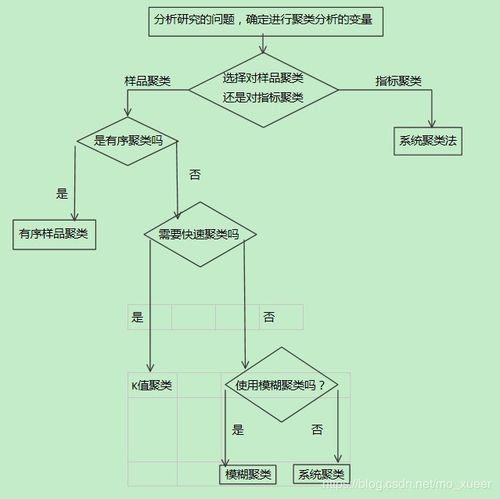
聚类的智慧:确定聚类的数量
在系统聚类中,确定聚类的数量是一个关键问题。你可以通过以下几种方法来解决这个问题:
- 轮廓系数:计算每个数据点在不同聚类中的轮廓系数,选择轮廓系数最大的聚类数量。
- 肖特利指数:计算不同聚类数量下的肖特利指数,选择指数最小的聚类数量。
- 聚类轮廓图:绘制聚类轮廓图,观察轮廓系数的变化趋势,选择合适的聚类数量。
R语言的魔法:系统聚类的实践
现在,让我们用R语言来实践一下系统聚类吧!以下是一个简单的例子:
```R
加载数据
data(iris)
提取数值变量
data_matrix <- iris[, -5]
计算距离矩阵
distance_matrix <- dist(data_matrix, method = \euclidean\)
进行层次聚类
hierarchical_clustering <- hclust(distance_matrix)
绘制聚类树
plot(hierarchical_clustering)
根据轮廓系数确定聚类数量
silhouette_score <- silhouette(hierarchical_clustering)
print(silhouette_score)
根据轮廓系数选择聚类数量
optimal_clusters <- cutree(hierarchical_clustering, k = 3)
print(optimal_clusters)
通过以上代码,我们可以对鸢尾花数据集进行系统聚类,并确定最佳的聚类数量。
系统聚类的魅力:探索数据的奥秘
系统聚类就像是一把钥匙,打开了数据世界的神秘之门。通过R语言,我们可以轻松地探索数据的奥秘,发现隐藏在数据背后的规律。让我们一起用系统聚类,开启数据的魔法之旅吧!
相关推荐



教程资讯
教程资讯排行









