
r语言 系统聚类,R语言系统聚类方法应用概述
时间:2025-01-20 来源:网络 人气:
你有没有想过,数据里的秘密就像藏宝图一样,等着我们去一一揭开?今天,咱们就来聊聊如何用R语言这个强大的工具,来玩转系统聚类,把那些看似杂乱无章的数据,变成一个个有故事的类别。
R语言:数据世界的魔法师

R语言,这个名字听起来就像是从科幻小说里跳出来的。但别小看了它,这可是数据分析界的大神,无论是统计建模、机器学习还是数据可视化,R语言都能轻松驾驭。而今天,我们要用它来玩转系统聚类,让数据说话。
系统聚类:数据的秘密花园
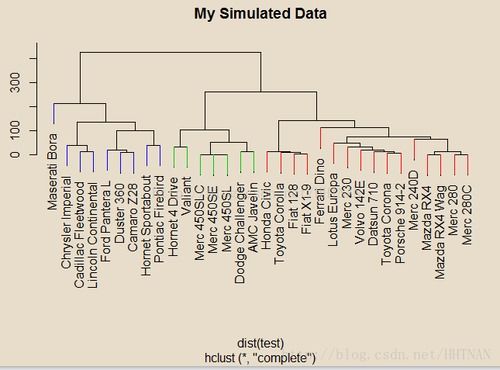
系统聚类,听起来是不是有点神秘?其实,它就像是一个秘密花园,把相似的数据点都聚集在一起,形成一个个小圈子。在这个花园里,每个数据点都是一朵花,而系统聚类就是那个园艺师,负责把相似的花朵分到一起。
R语言中的系统聚类:实操指南
那么,如何在R语言中实现系统聚类呢?别急,我来一步步教你。
第一步:准备数据
首先,你得有一堆数据。这些数据可以是任何形式,比如数值型、分类型,甚至是混合型。不过,记得数据要干净,别有缺失值,否则R语言会跟你急的。
第二步:计算距离
这一步,我们要计算数据点之间的距离。R语言提供了`dist()`函数,可以轻松计算各种距离,比如欧式距离、曼哈顿距离、兰氏距离等等。你可以根据自己的需求选择合适的距离度量方法。
第三步:选择聚类方法
系统聚类有很多种方法,比如最短距离法、最长距离法、类平均法、重心法等等。每种方法都有它的特点,你可以根据自己的需求选择合适的聚类方法。
第四步:聚类分析
这一步,我们使用`hclust()`函数进行聚类分析。这个函数会根据你选择的距离和聚类方法,生成一棵聚类树。你可以通过`plot()`函数来可视化这棵树。
第五步:分类
你可以根据聚类树,将数据点分到不同的类别中。R语言提供了`cutree()`函数,可以帮助你完成这个任务。
案例分析:城镇居民消费结构聚类研究
为了让大家更直观地理解系统聚类,我们来举个例子。假设我们有一份数据,包含了31个地区的8种消费支出指标,比如人均食品、衣着、医疗保健等支出。我们可以使用系统聚类来分析这些数据,看看哪些地区的消费结构相似。
首先,我们使用`dist()`函数计算距离矩阵,然后使用`hclust()`函数进行聚类分析。我们使用`cutree()`函数将数据点分到不同的类别中。通过分析聚类结果,我们可以发现哪些地区的消费结构相似,哪些地区有明显的差异。
:R语言系统聚类的魅力
通过R语言进行系统聚类,我们可以轻松地将数据点分到不同的类别中,发现数据背后的规律。这个过程就像是在探索一个神秘的宝藏,充满了乐趣和挑战。所以,别再犹豫了,快来试试R语言系统聚类吧!相信我,你一定会爱上它的!
相关推荐



教程资讯
教程资讯排行









