
spark对系统日志的,基于Spark的实时系统日志分析与处理技术概述
时间:2025-01-18 来源:网络 人气:
你有没有想过,那些看似杂乱无章的系统日志,其实隐藏着巨大的秘密呢?没错,就是那些记录着服务器运行状况、用户行为、系统异常的日志文件。今天,就让我带你一探究竟,看看Spark是如何对这些看似无趣的日志进行深度挖掘,揭示其中的奥秘吧!
一、Spark,日志分析的小能手
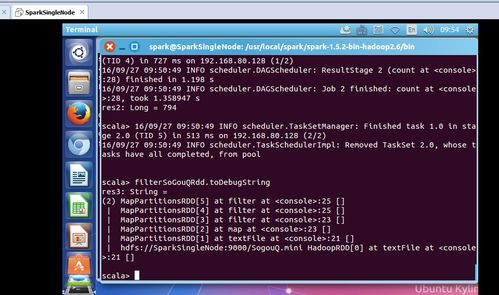
提起Spark,你可能会想到大数据处理、实时计算这些高大上的词汇。没错,Spark就是这样一个强大的工具,它能够轻松应对海量数据的处理和分析。而在系统日志分析领域,Spark更是如鱼得水。
为什么说Spark是日志分析的小能手呢?原因有以下几点:
1. 分布式处理能力:Spark支持分布式计算,能够将海量日志数据分散到多个节点上进行处理,大大提高了分析效率。
2. 丰富的API接口:Spark提供了丰富的API接口,包括Scala、Java、Python等,方便开发者根据自己的需求进行定制化开发。
3. 实时计算能力:Spark Streaming模块可以实现实时数据流处理,对系统日志进行实时分析,及时发现异常情况。
二、Spark分析系统日志的步骤

那么,Spark是如何分析系统日志的呢?下面,我们就来一步步揭开这个神秘的面纱。
1. 数据采集:首先,需要将系统日志采集到Spark环境中。这可以通过Flume、Logstash等工具实现,将日志数据导入到Spark集群中。
2. 数据预处理:采集到的原始日志数据往往包含大量的噪声和冗余信息,需要进行预处理。例如,去除空行、过滤掉无关字段等。
3. 数据转换:将预处理后的数据转换为Spark能够处理的数据结构,如RDD(弹性分布式数据集)或DataFrame。
4. 数据分析:利用Spark提供的API接口,对转换后的数据进行各种分析操作,如统计、过滤、排序等。
5. 结果展示:将分析结果以图表、报表等形式展示出来,方便用户直观地了解系统日志的情况。
三、Spark在系统日志分析中的应用案例

下面,我们来看几个Spark在系统日志分析中的应用案例:
1. 异常检测:通过分析系统日志,可以及时发现系统异常,如CPU使用率过高、内存溢出等。例如,可以使用Spark MLlib模块进行异常检测,对日志数据进行聚类分析,找出异常模式。
2. 用户行为分析:通过对用户访问日志进行分析,可以了解用户行为特征,如用户访问频率、页面浏览顺序等。这有助于优化网站设计和提高用户体验。
3. 性能监控:通过分析系统日志,可以监控系统性能指标,如响应时间、吞吐量等。这有助于及时发现性能瓶颈,优化系统性能。
四、Spark在日志分析中的优势
相比于其他日志分析工具,Spark在以下方面具有明显优势:
1. 高效性:Spark的分布式处理能力,使得日志分析效率大大提高。
2. 灵活性:Spark支持多种编程语言,方便开发者根据自己的需求进行定制化开发。
3. 可扩展性:Spark可以轻松扩展到大规模集群,满足不同规模日志分析的需求。
五、
Spark在系统日志分析领域具有广泛的应用前景。通过Spark,我们可以轻松挖掘系统日志中的价值,为系统优化、性能监控、用户行为分析等提供有力支持。相信在未来的日子里,Spark将会在日志分析领域发挥越来越重要的作用。那么,你准备好用Spark开启你的日志分析之旅了吗?
相关推荐



教程资讯
教程资讯排行









