
python 爬虫系统,Python爬虫技术在数据抓取与分析中的应用与实践
时间:2025-01-15 来源:网络 人气:
Python爬虫系统:揭秘网络数据的秘密捕手
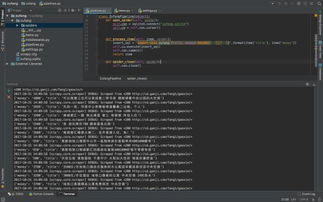
在数字化时代,数据如同空气般无处不在,它们静静地存在于各种网络平台中,等待着被发现、被解读。而在这数据的海洋里,Python爬虫系统就像是一艘精准的渔船,带领我们深入其中,捕捉那些隐藏的信息。
一、Python爬虫系统的魅力所在

Python,作为一种高级编程语言,以其简洁易读的语法和强大的库支持,赢得了众多开发者的喜爱。而Python爬虫系统,则是将这些优势发挥到了极致。它不仅能够高效地抓取网页数据,还能对数据进行深度解析和处理,为我们提供丰富的数据资源。
想象在搜索引擎中输入关键词,短短几秒钟内就能获得数百万条相关结果。这背后,就是Python爬虫系统的默默付出。它像是一位不知疲倦的探险家,穿梭于网络的每一个角落,寻找着那些珍贵的信息。
二、Python爬虫系统的核心组件
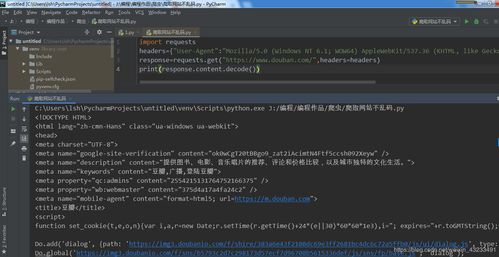
一个完整的Python爬虫系统通常包括以下几个核心组件:
1. 网络请求模块:负责向目标网站发送请求,并获取网页内容。
2. 解析模块:利用BeautifulSoup、lxml等库对抓取到的网页内容进行解析,提取出我们需要的数据。
3. 存储模块:将解析后的数据保存到数据库或文件中,以便后续分析和使用。
4. 反爬虫策略模块:针对一些常见的反爬虫措施,如IP封禁、验证码等,制定相应的应对策略。
三、Python爬虫系统的应用场景
Python爬虫系统的应用场景非常广泛,以下是一些典型的例子:
1. 数据挖掘:通过爬取公开的数据集,进行数据清洗、特征提取等操作,为机器学习和深度学习提供数据支持。
2. 市场调研:对企业官网、社交媒体等进行爬取,了解行业动态、竞争对手情况等,为企业决策提供参考依据。
3. 舆情监测:实时抓取网络舆情信息,分析公众情绪和观点,为公关和市场营销提供数据支持。
4. 内容创作:从新闻网站、博客等平台抓取优质内容,为内容创作者提供灵感来源。
四、Python爬虫系统的挑战与应对
尽管Python爬虫系统具有很多优点,但在实际应用中也会遇到一些挑战:
1. 反爬虫策略:一些网站会采取各种措施限制爬虫的访问,如设置访问速度限制、使用验证码等。针对这些情况,我们可以采用代理IP、设置合理的请求间隔等方法来应对。
2. 法律合规性问题:在爬取数据时,我们需要遵守相关法律法规和网站的使用协议。未经授权擅自抓取和使用他人数据可能会触犯法律。因此,在进行爬虫开发前,我们需要充分了解相关法律法规,并确保我们的行为合法合规。
3. 数据质量:由于网络环境的复杂性,抓取到的数据可能存在不准确、不完整等问题。为了提高数据质量,我们需要对数据进行多轮清洗和验证。
五、Python爬虫系统的未来展望
随着技术的不断进步和应用场景的拓展,Python爬虫系统将迎来更加广阔的发展空间。未来,我们可以期待以下几个方面的发展:
1. 智能化与自动化:通过引入人工智能技术,让爬虫系统更加智能地识别和解析网页内容,减少人工干预的需求。
2. 分布式爬取:利用分布式计算框架如Scrapy-Redis等,实现多节点协同爬取,提高爬虫的效率和稳定性。
3. 隐私保护与安全传输:随着数据隐私和安全问题的日益突出,如何在爬虫系统中保护用户隐私和确保数据传输安全将成为重要研究方向。
Python爬虫系统作为网络数据的捕手,正以其独特的魅力和强大的功能,在数字化时代发挥着越来越重要的作用。让我们一起探索这个充满无限可能的领域吧!


教程资讯
教程资讯排行









