
mahout 推荐系统,协同过滤算法与Hadoop分布式实现
时间:2024-12-30 来源:网络 人气:
你有没有想过,当你打开某款购物APP,它就能精准地推荐给你心仪的商品?或者当你刷完一部电影,APP又神奇地为你推荐了下一部你可能会喜欢的电影?这一切的背后,都离不开一个强大的工具——推荐系统。今天,就让我带你走进这个神秘的世界,揭开Mahout推荐系统的神秘面纱。
一、初识Mahout:一个骑象人的智慧

说到推荐系统,不得不提一个名字——Mahout。它就像一个骑象人,驾驭着Hadoop这头大象,在机器学习的海洋中畅游。Mahout是一个开源的机器学习框架,它集成了大量的常用算法,其中就包括推荐算法。它支持在Hadoop分布式环境下运行,大大提高了数据处理的速度和效率。
二、Taste接口:推荐系统的灵魂
在Mahout的世界里,有一个叫做Taste的接口,它是推荐系统的灵魂。Taste定义了一系列的接口和类,用于构建、评估和运行推荐系统。它就像一个工厂,生产出各种各样的推荐算法。
三、单机内存算法:小试牛刀
单机内存算法是Mahout推荐系统的基础,它适用于处理中小规模的数据。比如,我们熟悉的UserCF和ItemCF算法,就可以在单机内存算法的基础上实现。虽然单机内存算法的威力有限,但对于中小规模的数据来说,已经足够应对。
四、分布式算法:大象的力量
当数据规模越来越大时,单机内存算法就显得力不从心。这时,就需要借助Hadoop的分布式计算能力。Mahout提供了基于Hadoop的分布式算法实现,可以将大规模数据分布到多个节点上进行处理,大大提高了计算效率。
五、算法评判标准:召回率与准确率
一个优秀的推荐系统,不仅要推荐出用户喜欢的商品或内容,还要尽可能多地推荐。这就涉及到两个重要的指标:召回率和准确率。召回率是指推荐系统推荐出的商品或内容中,用户真正喜欢的比例;准确率则是指推荐系统推荐出的商品或内容中,用户实际购买或观看的比例。
六、推荐算法大揭秘
在Mahout中,有许多经典的推荐算法,比如:
基于用户的协同过滤算法(UserCF):通过分析用户之间的相似度,为用户推荐他们可能喜欢的商品或内容。
基于物品的协同过滤算法(ItemCF):通过分析商品之间的相似度,为用户推荐他们可能喜欢的商品或内容。
SlopeOne算法:通过计算商品之间的差异,为用户推荐他们可能喜欢的商品或内容。
KNN Linear interpolation item-based推荐算法:通过分析用户对商品的评分,为用户推荐他们可能喜欢的商品或内容。
SVD推荐算法:通过矩阵分解,为用户推荐他们可能喜欢的商品或内容。
Tree Cluster-based推荐算法:通过聚类分析,为用户推荐他们可能喜欢的商品或内容。
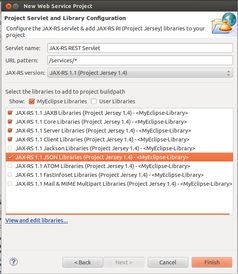
七、实战演练:搭建REST风格简单推荐系统
想要亲身体验Mahout推荐系统的魅力吗?那就跟我一起来搭建一个简单的REST风格推荐系统吧!首先,我们需要创建一个MyEclipse Web Service Project,并添加Mahout的相关库。编写一个简单的REST接口,用于接收用户请求,并返回推荐结果。
八、:探索推荐系统的无限可能
Mahout推荐系统就像一个宝藏,等待着我们去挖掘。通过不断学习和实践,我们可以掌握更多的算法,为用户提供更加精准的推荐。让我们一起,在这个充满挑战和机遇的世界里,探索推荐系统的无限可能吧!
相关推荐


教程资讯
教程资讯排行









