
python 爬虫 教务系统
时间:2024-12-14 来源:网络 人气:418
Python爬虫实战:教务系统信息抓取与处理
一、准备工作

在进行爬虫开发之前,我们需要做好以下准备工作:
1. 环境搭建
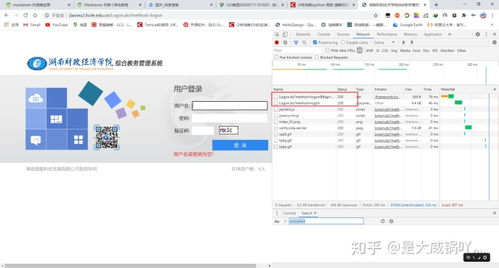
首先,确保你的计算机上已经安装了Python环境。如果没有,请访问Python官网下载并安装。
2. 安装库

接下来,我们需要安装一些常用的Python库,如requests、BeautifulSoup、pandas等。可以使用pip命令进行安装:
```bash
pip install requests beautifulsoup4 pandas
3. 了解教务系统

在编写爬虫之前,我们需要了解教务系统的结构和数据格式。可以通过查看网页源代码、使用浏览器开发者工具等方式来获取相关信息。
二、编写爬虫
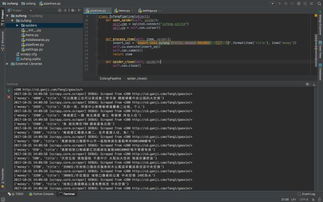
下面是一个简单的Python爬虫示例,用于抓取教务系统中的成绩信息。
```python
import requests
from bs4 import BeautifulSoup
设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
登录教务系统
def login(username, password):
url = 'http://jwc.example.com/login' 替换为你的教务系统登录地址
data = {
'username': username,
'password': password
}
response = requests.post(url, headers=headers, data=data)
return response.cookies
获取成绩信息
def get_grades(cookies):
url = 'http://jwc.example.com/grades' 替换为你的教务系统成绩查询地址
response = requests.get(url, headers=headers, cookies=cookies)
soup = BeautifulSoup(response.text, 'html.parser')
grades = soup.find_all('tr') 假设成绩信息在表格中
for grade in grades:
解析表格数据
...
print(grade)
主函数
def main():
username = 'your_username' 替换为你的用户名
password = 'your_password' 替换为你的密码
cookies = login(username, password)
get_grades(cookies)
if __name__ == '__main__':
main()
三、数据解析与处理
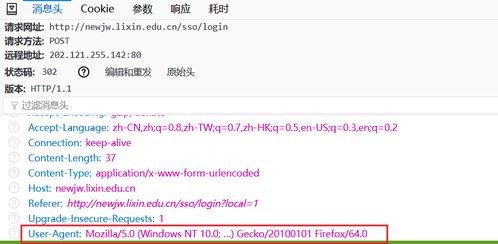
在获取到教务系统信息后,我们需要对数据进行解析和处理。以下是一个简单的示例,用于解析成绩信息:
```python
def parse_grades(grades):
解析成绩信息
...
return grades
主函数
def main():
...
grades = get_grades(cookies)
parsed_grades = parse_grades(grades)
处理解析后的数据
...
if __name__ == '__main__':
main()
本文介绍了如何使用Python编写爬虫,实现对教务系统信息的自动抓取与处理。通过学习本文,你可以了解到爬虫的基本原理和实现方法,为以后开发更复杂的爬虫项目打下基础。
五、注意事项

在编写爬虫时,需要注意以下事项:
- 尊重网站版权,不要进行非法抓取。
- 避免对网站造成过大压力,合理设置爬取频率。
- 注意个人隐私,不要泄露用户信息。
通过本文的学习,相信你已经掌握了Python爬虫的基本技能。在实际应用中,你可以根据自己的需求,不断优化和扩展爬虫功能。祝你学习愉快!




教程资讯
教程资讯排行









