
spark开源系统,开源大数据处理框架的引领者
时间:2024-12-03 来源:网络 人气:
Apache Spark:开源大数据处理框架的引领者
随着大数据时代的到来,如何高效处理和分析海量数据成为企业关注的焦点。Apache Spark作为一款开源的大数据处理框架,凭借其高性能、易用性和丰富的功能,成为了大数据领域的引领者。
一、Spark的起源与发展
Apache Spark最初由加州大学伯克利分校的AMP实验室开发,旨在解决Hadoop MapReduce在处理速度和编程模型上的局限性。自2009年开源以来,Spark迅速发展成为一个功能丰富、性能卓越的大数据生态系统。
Spark的创始人Matei Zaharia在2013年将Spark捐赠给了Apache软件基金会,使其成为Apache的一个顶级项目。如今,Spark已经成为大数据领域的事实标准,广泛应用于各个行业。
二、Spark的核心特性
1. 高性能:Spark采用内存计算技术,将数据处理工作流转化为内存中的计算,从而显著提高数据处理速度。
2. 易用性:Spark支持多种编程语言,包括Java、Scala、Python和R,开发者可以使用自己熟悉的语言进行开发。
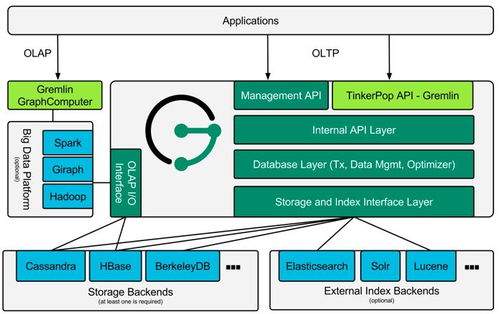
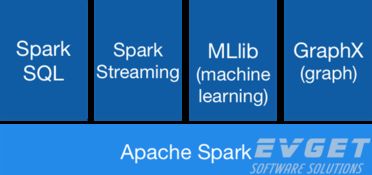
3. 丰富的生态系统:Spark生态系统包含了多个核心模块,如Spark SQL、Spark Streaming、MLlib(机器学习库)、GraphX(图计算库)等,满足不同应用需求。
4. 分布式计算框架:Spark能够横跨多个节点并行处理数据,适用于大规模数据集。
三、Spark的应用场景
1. 批量处理:Spark能够处理大型的批量数据,尤其适合需要快速分析和计算的场景,如日常数据。
2. 实时计算:Spark Streaming模块能够实时处理动态数据流,适用于实时数据分析、监控和预警。
3. 机器学习:MLlib库提供了丰富的机器学习算法和实用程序,如分类、回归、聚类等,适用于构建智能应用。
4. 图计算:GraphX模块提供了分布式图形处理框架,适用于构建和分析大型图形。
四、Spark的优势
1. 速度快:Spark采用内存计算技术,数据处理速度比传统Hadoop MapReduce快100倍以上。
2. 易用性:Spark支持多种编程语言,降低了开发门槛。
3. 通用性:Spark适用于各种类型的数据处理任务,包括批处理、实时计算、机器学习和图计算。
4. 兼容性:Spark能够与多种数据源集成,如Hadoop分布式文件系统(HDFS)、Apache Cassandra、Apache HBase和Amazon S3等。
5. 容错性:Spark具有强大的容错能力,能够在节点故障的情况下自动恢复数据。
五、Spark的未来发展
随着大数据技术的不断发展,Spark也在不断优化和升级。未来,Spark将继续关注以下几个方面的发展:
1. 性能优化:进一步提升Spark的性能,使其在处理大规模数据集时更加高效。
2. 生态扩展:丰富Spark生态系统,增加更多功能模块,满足更多应用需求。
3. 跨平台支持:支持更多操作系统和硬件平台,提高Spark的适用范围。
4. 开源社区建设:加强开源社区建设,吸引更多开发者参与,共同推动Spark的发展。
Apache Spark作为一款开源的大数据处理框架,凭借其高性能、易用性和丰富的功能,已经成为大数据领域的引领者。随着大数据技术的不断发展,Spark将继续发挥其优势,为各行各业提供高效、可靠的大数据处理解决方案。


教程资讯
教程资讯排行









