
spark推荐系统,构建高效、精准的推荐解决方案
时间:2024-11-27 来源:网络 人气:
Spark推荐系统:构建高效、精准的推荐解决方案
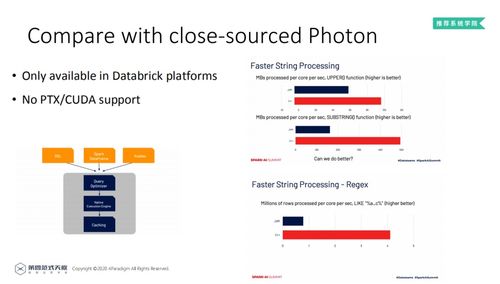
一、Spark推荐系统概述

Spark推荐系统是基于Spark大数据处理框架构建的,旨在解决大规模推荐场景下的计算效率问题。与传统推荐系统相比,Spark推荐系统具有以下特点:
分布式计算:Spark支持分布式计算,能够处理海量数据,提高推荐系统的处理能力。
内存计算:Spark采用内存计算技术,减少数据读取和写入磁盘的次数,提高计算速度。
弹性扩展:Spark支持弹性扩展,可根据实际需求动态调整资源,提高推荐系统的稳定性。
二、Spark推荐系统原理
Spark推荐系统主要基于协同过滤算法,包括以下两种类型:
基于用户的协同过滤(User-based CF):通过分析用户之间的相似度,为用户推荐相似用户喜欢的物品。
基于物品的协同过滤(Item-based CF):通过分析物品之间的相似度,为用户推荐相似物品。
Spark推荐系统的工作流程如下:
数据预处理:对原始数据进行清洗、去重、特征提取等操作。
相似度计算:计算用户或物品之间的相似度,通常采用余弦相似度、皮尔逊相关系数等方法。
推荐生成:根据相似度计算结果,为用户推荐相似用户或物品。
评估与优化:对推荐结果进行评估,根据评估结果优化推荐算法。
三、Spark推荐系统应用场景
Spark推荐系统在多个领域具有广泛的应用,以下列举几个典型应用场景:
电子商务:为用户推荐商品,提高用户购买转化率。
视频推荐:为用户推荐视频内容,提高用户观看时长。
新闻推荐:为用户推荐新闻内容,提高用户阅读兴趣。
社交网络:为用户推荐好友,扩大用户社交圈。
四、Spark推荐系统实现方法
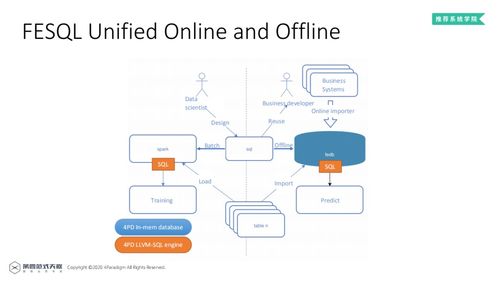
以下是一个基于Spark的推荐系统实现方法示例:
数据预处理:使用Spark SQL读取原始数据,进行清洗、去重、特征提取等操作。
相似度计算:使用Spark MLlib中的相似度计算函数,计算用户或物品之间的相似度。
推荐生成:使用Spark MLlib中的推荐算法,为用户生成推荐列表。
评估与优化:使用A/B测试等方法评估推荐效果,根据评估结果优化推荐算法。
Spark推荐系统凭借其高性能、分布式计算和内存计算等优势,在推荐系统领域具有广泛的应用前景。通过本文的介绍,读者可以了解到Spark推荐系统的原理、应用场景以及实现方法,为实际项目开发提供参考。
相关推荐



教程资讯
教程资讯排行









