
spark 文件系统,架构、特性与应用
时间:2024-11-18 来源:网络 人气:
深入解析Spark文件系统:架构、特性与应用

随着大数据时代的到来,大数据处理技术得到了迅速发展。Apache Spark作为一款高性能的大数据处理引擎,在处理大规模数据集方面表现出色。Spark文件系统(Spark FileSystem)作为Spark的核心组件之一,负责数据的存储和访问。本文将深入解析Spark文件系统的架构、特性以及应用场景。
一、Spark文件系统概述
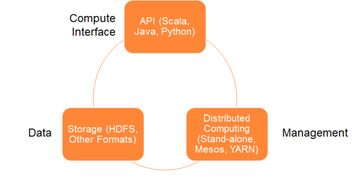
Spark文件系统是Spark框架中负责数据存储和访问的组件。它支持多种文件存储系统,如HDFS、本地文件系统、Amazon S3等。Spark文件系统为Spark应用程序提供了统一的抽象接口,使得开发者可以方便地在不同的存储系统之间进行数据迁移和操作。
二、Spark文件系统架构
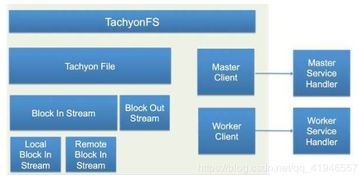
Spark文件系统架构主要包括以下几个部分:
SparkConf:用于定义Spark应用程序的配置信息,如存储系统类型、文件路径等。
SparkContext:Spark应用程序的入口,负责初始化Spark文件系统,并封装了网络通信、分布式、消息机制、存储、计算、运维监控、文件系统等各类常用功能。
StorageSystem:存储系统接口,定义了Spark文件系统需要实现的基本操作,如文件读取、写入、删除等。
StorageHandler:存储系统实现类,负责与具体的存储系统进行交互,如HDFS、本地文件系统等。
三、Spark文件系统特性
Spark文件系统具有以下特性:
跨存储系统支持:Spark文件系统支持多种存储系统,如HDFS、本地文件系统、Amazon S3等,方便用户在不同存储系统之间进行数据迁移和操作。
统一抽象接口:Spark文件系统为Spark应用程序提供了统一的抽象接口,使得开发者可以方便地在不同的存储系统之间进行数据操作。
高性能:Spark文件系统在读取和写入数据时,采用了高效的算法和优化策略,保证了数据处理的性能。
容错性:Spark文件系统支持数据副本机制,确保了数据的可靠性和容错性。
四、Spark文件系统应用场景
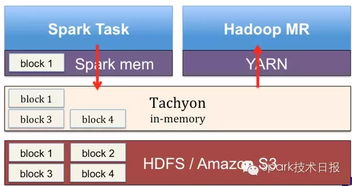
Spark文件系统在以下场景中具有广泛的应用:
大数据处理:Spark文件系统可以与Spark计算引擎结合,实现大规模数据集的分布式处理。
数据迁移:Spark文件系统支持多种存储系统,方便用户在不同存储系统之间进行数据迁移。
数据备份:Spark文件系统支持数据副本机制,可以用于数据的备份和恢复。
数据共享:Spark文件系统可以用于在多个Spark应用程序之间共享数据。
Spark文件系统作为Spark框架的核心组件之一,在数据处理领域发挥着重要作用。它具有跨存储系统支持、统一抽象接口、高性能和容错性等特性,为Spark应用程序提供了强大的数据存储和访问能力。随着大数据技术的不断发展,Spark文件系统将在更多场景中得到应用。
相关推荐

教程资讯
教程资讯排行









