
spark系统架构,Spark系统架构详解
时间:2024-11-17 来源:网络 人气:
Spark系统架构详解
随着大数据时代的到来,处理海量数据的需求日益增长。Apache Spark作为一种快速、通用的大数据处理框架,因其高效的性能和丰富的功能而受到广泛关注。本文将详细介绍Spark的系统架构,帮助读者更好地理解其工作原理。
一、Spark概述
Apache Spark是一个开源的分布式计算系统,旨在处理大规模数据集。它提供了快速的查询处理能力,支持多种编程语言,如Java、Scala和Python。Spark的核心是弹性分布式数据集(RDD),它是一种可并行操作的分布式数据结构。
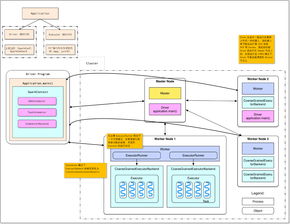
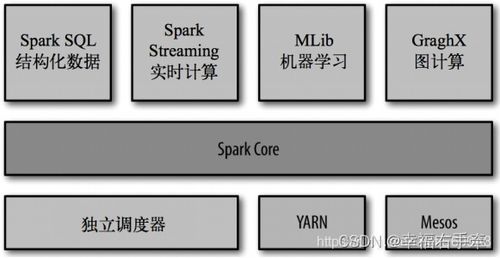
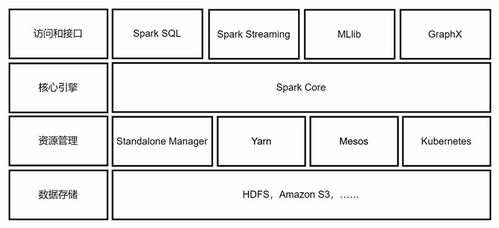
二、Spark系统架构
Spark的系统架构可以分为以下几个关键部分:
2.1 Spark Core
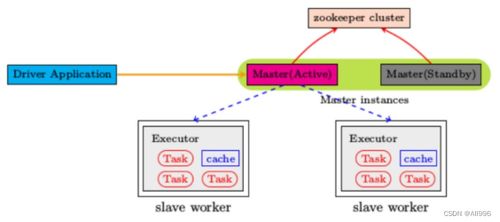
Spark Core是Spark的基础模块,提供了RDD(弹性分布式数据集)抽象、任务调度和内存管理等功能。RDD是Spark的核心数据结构,它允许用户以编程方式在集群上对数据进行分布式处理。
2.2 Spark SQL
Spark SQL是Spark的一个模块,用于处理结构化数据。它支持多种数据源,如关系数据库、Hive和JSON文件。Spark SQL提供了类似SQL的查询语言,使得用户可以轻松地对结构化数据进行查询和分析。
2.3 Spark Streaming
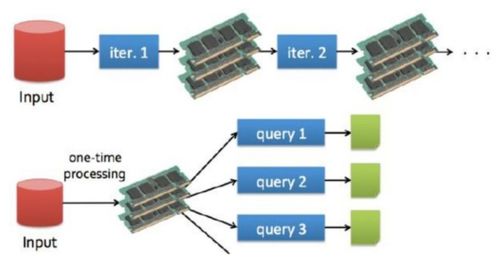
Spark Streaming是Spark的一个模块,用于实时数据处理。它允许用户以高吞吐量处理实时数据流,并支持多种数据源,如Kafka、Flume和Twitter。Spark Streaming提供了类似于Spark Core的API,使得用户可以方便地处理实时数据。
2.4 MLlib
MLlib是Spark的一个机器学习库,提供了多种机器学习算法和工具。它支持多种机器学习任务,如分类、回归、聚类和协同过滤。MLlib旨在简化机器学习模型的开发和应用。
2.5 GraphX
GraphX是Spark的一个图形处理库,用于处理大规模图数据。它提供了丰富的图形算法和操作,如图遍历、图过滤和图连接。GraphX使得用户可以轻松地在Spark上处理和分析图数据。
三、Spark运行时环境
Spark的运行时环境主要包括以下几个部分:
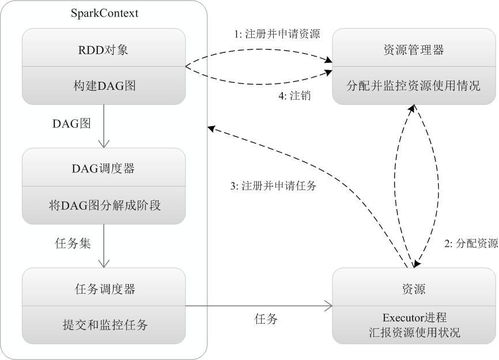
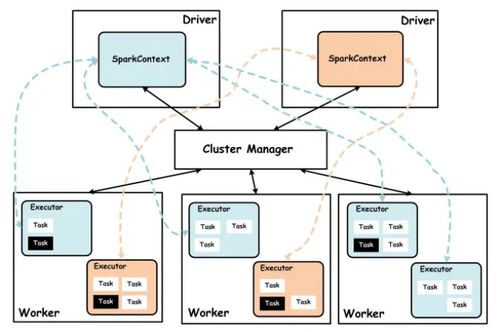
3.1 SparkContext
SparkContext是Spark应用程序的入口点,它负责初始化Spark的运行时环境。SparkContext负责与集群资源管理器(如YARN、Mesos或Spark Standalone)通信,并创建RDD和其他Spark组件。
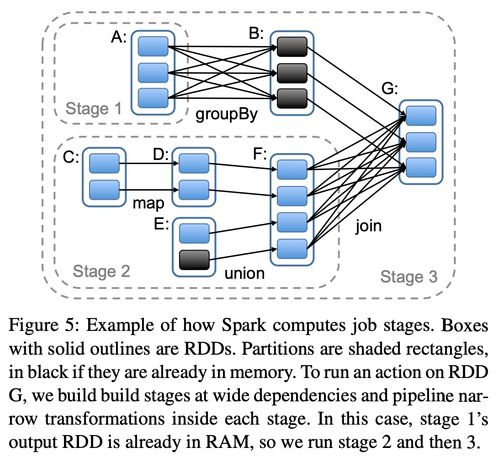
3.2 DAGScheduler
DAGScheduler是Spark的任务调度器,它负责将用户编写的RDD转换操作转换为物理执行计划。DAGScheduler将执行计划分解为一系列的阶段(Stage),并调度这些阶段在集群上执行。
3.3 TaskScheduler
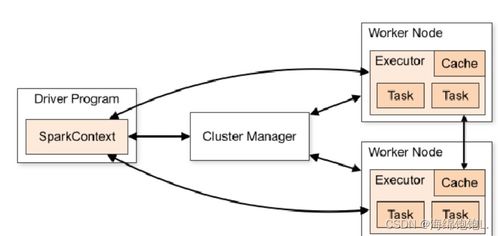
TaskScheduler负责将DAGScheduler生成的阶段分配给集群中的执行器(Executor)。它将阶段分解为任务(Task),并将任务发送到执行器上执行。
Apache Spark是一个功能强大且高效的大数据处理框架。本文详细介绍了Spark的系统架构,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX等模块,以及Spark的运行时环境。通过理解Spark的系统架构,用户可以更好地利用Spark处理大规模数据集,并开发出高性能的大数据处理应用程序。
相关推荐
教程资讯
教程资讯排行









