
spark mlib 推荐系统,构建高效推荐系统的利器
时间:2024-11-16 来源:网络 人气:
Spark MLlib:构建高效推荐系统的利器
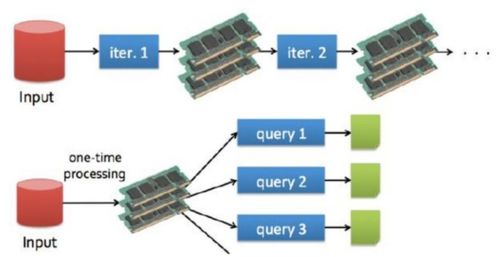
一、Spark MLlib简介
Apache Spark是一个开源的分布式计算系统,旨在处理大规模数据集。Spark MLlib是Spark的一个模块,提供了多种机器学习算法,包括分类、回归、聚类、协同过滤等。MLlib的设计理念是易于使用、可扩展且高效,这使得它在处理大规模数据时具有显著优势。
二、推荐系统概述
推荐系统是一种信息过滤系统,旨在根据用户的兴趣和偏好,向用户推荐相关的内容或商品。推荐系统通常分为基于内容的推荐和基于协同过滤的推荐两种类型。基于内容的推荐系统通过分析用户的历史行为和内容特征,为用户推荐相似的内容;而基于协同过滤的推荐系统则通过分析用户之间的相似性,为用户推荐其他用户喜欢的内容。
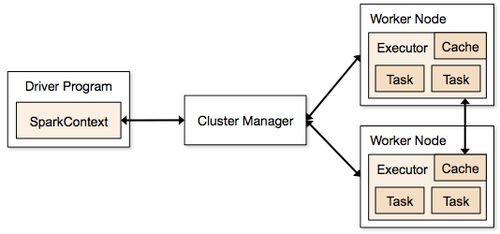
三、Spark MLlib在推荐系统中的应用

3.1 协同过滤算法
协同过滤是推荐系统中最常用的算法之一,它通过分析用户之间的相似性来推荐内容。Spark MLlib提供了两种协同过滤算法:基于内存的协同过滤和基于模型的协同过滤。
基于内存的协同过滤算法通过计算用户之间的相似度来推荐内容,这种方法简单易实现,但计算复杂度较高。基于模型的协同过滤算法则通过构建一个预测模型来预测用户对未知项目的评分,这种方法可以处理大规模数据集,但需要更多的计算资源。
3.2 机器学习算法
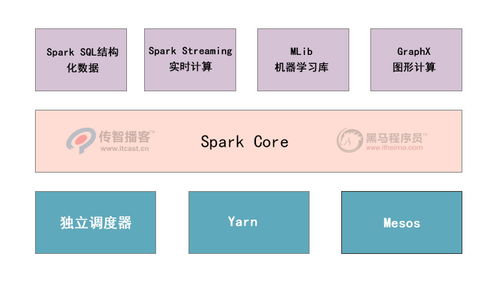
Spark MLlib提供了多种机器学习算法,如逻辑回归、决策树、随机森林等,这些算法可以用于构建推荐系统的预测模型。例如,可以使用逻辑回归来预测用户对商品的评分,然后根据预测结果推荐商品。
3.3 特征工程

特征工程是推荐系统中的关键步骤,它涉及到从原始数据中提取出对模型有用的特征。Spark MLlib提供了多种特征提取和转换工具,如向量奇异值分解(SVD)、词袋模型等,可以帮助用户进行特征工程。
四、Spark MLlib的优势
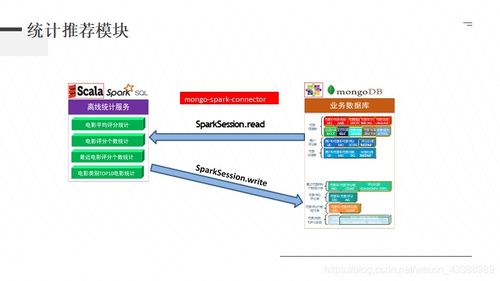
使用Spark MLlib构建推荐系统具有以下优势:
高效:Spark MLlib利用了Spark的分布式计算能力,可以高效地处理大规模数据集。
可扩展:Spark MLlib支持多种机器学习算法,可以根据实际需求选择合适的算法。
易于使用:Spark MLlib提供了丰富的API,用户可以轻松地实现推荐系统。
社区支持:Spark拥有庞大的社区,用户可以从中获取帮助和资源。
Spark MLlib作为Apache Spark的机器学习库,为构建推荐系统提供了强大的支持。通过使用Spark MLlib,可以高效、可扩展地实现推荐系统,从而提升用户体验和业务价值。随着大数据时代的到来,Spark MLlib在推荐系统中的应用将越来越广泛。


教程资讯
教程资讯排行









